
Flexor for data & analytics departments
Structure the unstructured. Turn unstructured enterprise data into normalized, clean and standardized data you can query in SQL, just like structured data. Gain trusted, analysis-ready context for dashboards and forecasts, as well as agents and agentic systems, to empower your enterprise with faster, more informed decisions.

Unlock signals
trapped in unstructured data from multiple sources.

Faster
time to insight. No manual tagging and data wrangling.

Richer
dashboards and reporting, with sentiment, themes, churn indicators, intent signals & root causes.

Stronger
forecasting to improve planning accuracy.

Less analyst overhead
Focus on insight, modeling, and recommendations.
What leading data teams are building with Flexor

Use unstructured data like structured data
Query emails, documents, calls, tickets, and chats with the same ease as tables, with clean, unified, analysis-and-AI-ready data that fits seamlessly into your existing workflows.
Bring unstructured data into the business
Make contracts, conversations, PDFs, and internal knowledge accessible as usable data across the organization. What was once hidden or too messy to use becomes a driver of decisions, reporting, and strategy.
Empower every data practitioner with AI
Enable analysts, BI developers, and data engineers to work with unstructured data and AI without needing data science expertise.
Combine structured and unstructured data for full context
Enrich dashboards, models, and reports with the missing context from unstructured sources. For example, connect CRM records with calls, financial data with contracts, and product metrics with customer feedback.
Eliminate manual data preparation work
Automate cleaning, deduplication, parsing, classification, and enrichment of unstructured data. Free up time spent on brittle scripts and one-off processes.
Create a trusted, unified pane of truth
Standardize terminology, relationships, business logic and data context across all data. Give analysts, stakeholders, and executives confidence that every insight is grounded in consistent, complete organizational context.
Tackle the toughest challenges holding back your enterprise, today
Here are some of the ways enterprises use Flexor’s AI Context Engine, ACE, across departments.

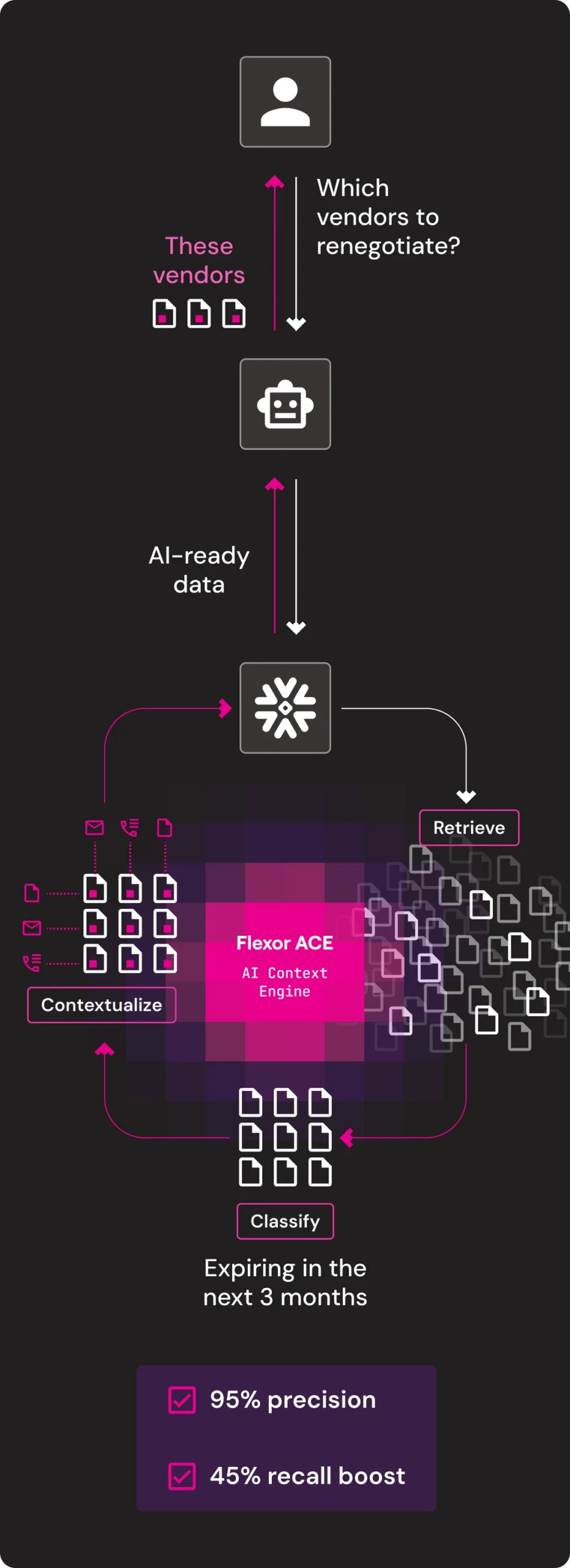
Procurement Optimization

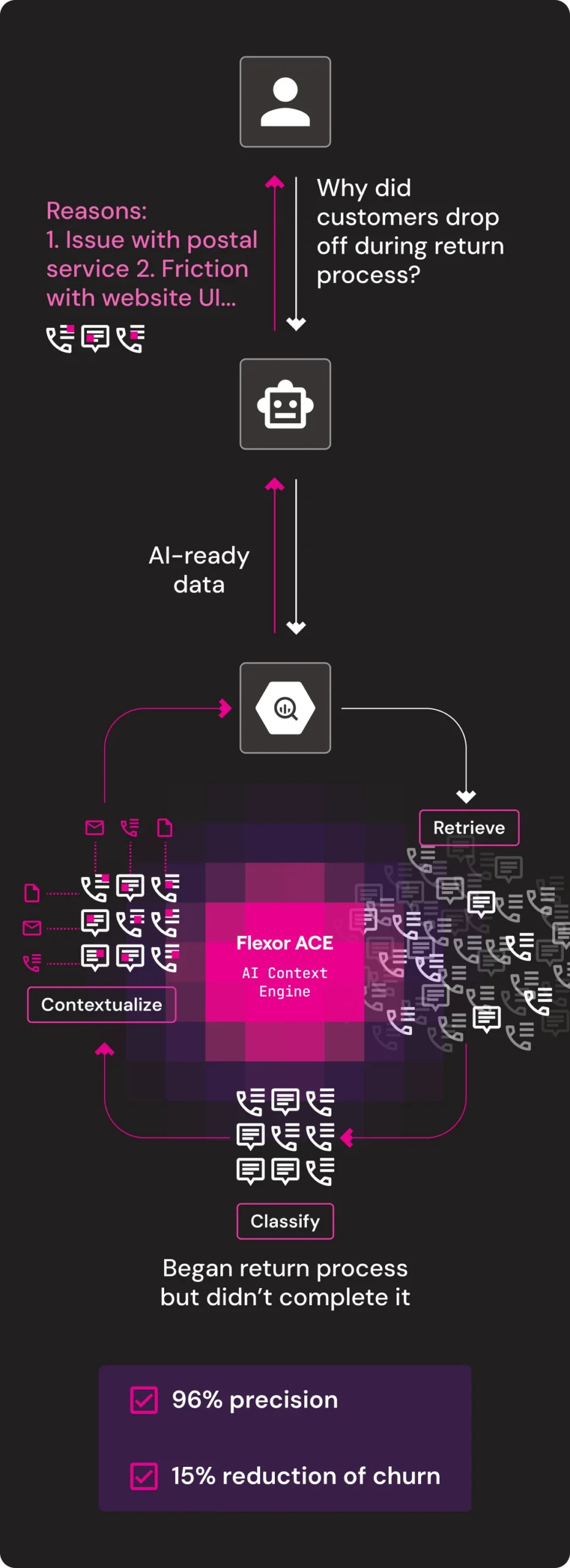
Churn Mitigation

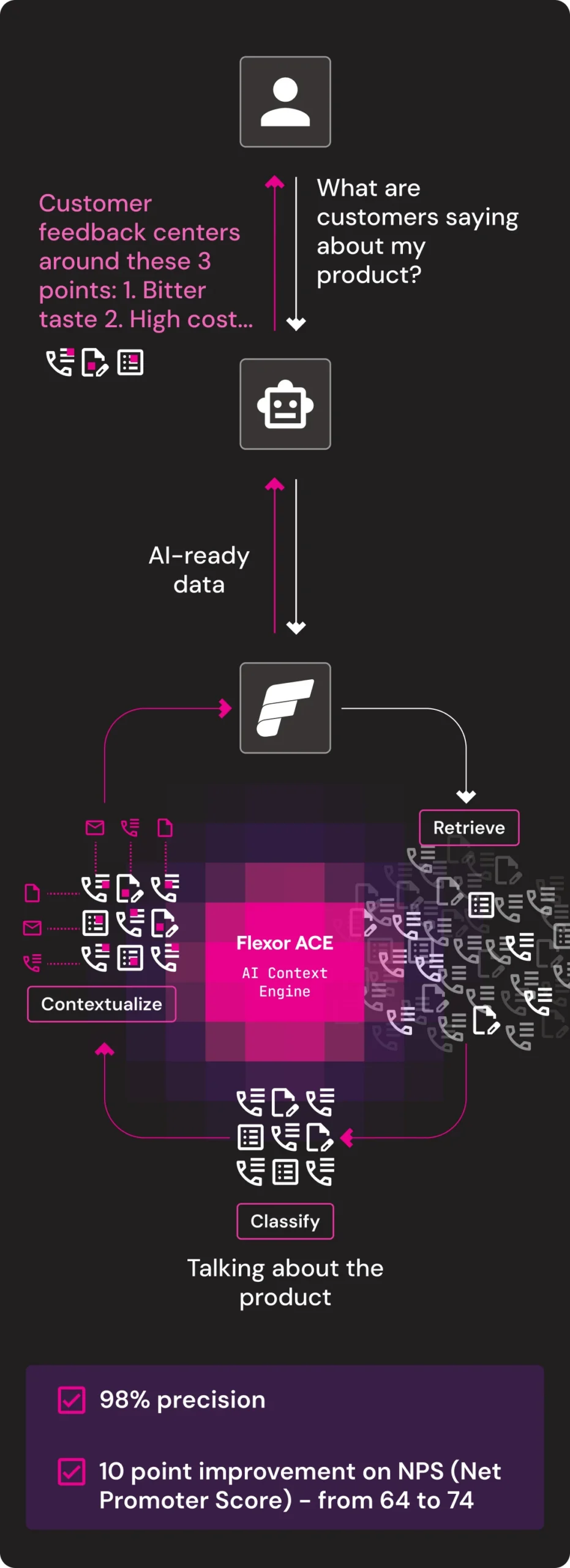
Product Discovery

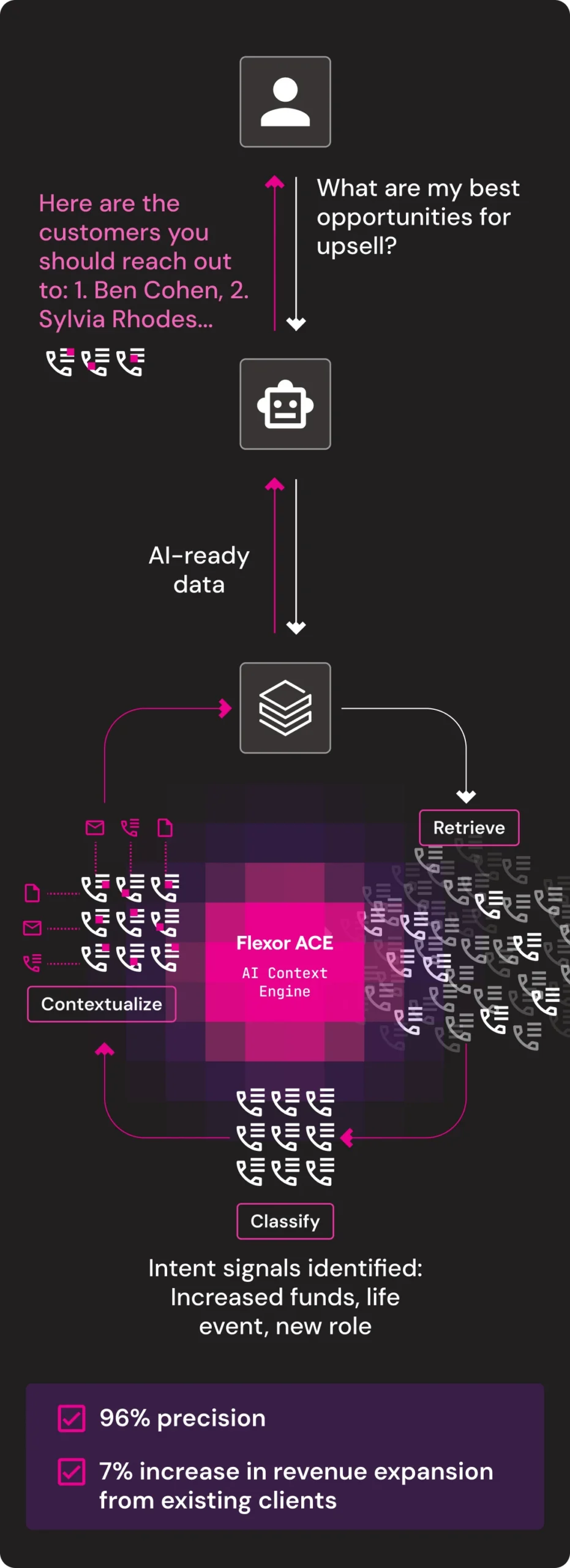
Upsell Identification

Portfolio Management
Procurement Optimization
Churn Mitigation
Product Discovery
Upsell Identification
Portfolio Management
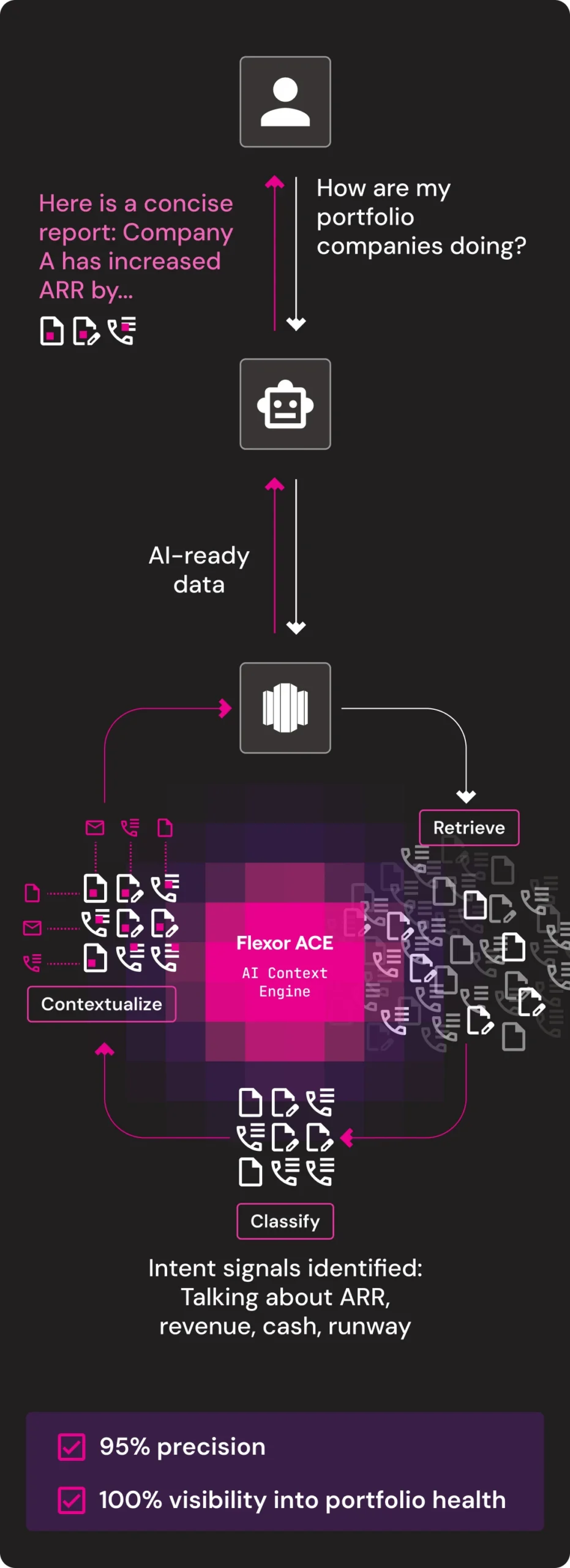
Structured data tells you what happened. Unstructured data tells you why.
Turn unstructured enterprise data into decision-ready insight with Flexor.
ACE integrates seamlessly with your existing stack
Provides enterprise-grade security and privacy
Flexor can be deployed in your VPC. Your data is never used to train models.
The technology abides by the highest privacy and security standards, always keeping your data secure.

Ready to give your AI agents the context they actually need?
Transform your unstructured data into a competitive advantage.
Frequently asked questions
What types of unstructured data can Flexor process?

All written unstructured data types: emails, tickets, surveys, contracts, transcripts, PDFs, CRM notes, chats, documents, vendor communications, internal knowledge, and more.
Does Flexor replace our BI platform?
No. Flexor strengthens your BI stack by making unstructured data usable in dashboards, reporting, and models. Flexor works directly on top of your data warehouse, without moving or duplicating sensitive data. We support data residency requirements, can be deployed in your VPC, and never uses your data to train external models.
How do we ensure extracted data is accurate?
Flexor ensures accuracy by “showing its work.” Every extracted data point is linked back to its original source document, giving you full AI explainability, data lineage and traceability. Easily verify where each insight came from, validate it in context, and maintain confidence in every decision.
Is the data secure and compliant?
Flexor is built with enterprise-grade security, governance, and data lineage tracking. It ensures sensitive data is handled securely while maintaining full visibility, data lineage, and auditability.
Does Flexor replace analysts?
No. It removes time-consuming manual work such as cleaning messy text, tagging records, consolidating sources, extracting key information, and preparing unstructured data for analysis. That allows analysts to spend more time on higher-value work like uncovering trends, building stronger models, advising stakeholders, shaping strategy, and driving business decisions with confidence.
