
Key Takeaways
- AI infrastructure is designed to support AI-specific workloads, including model training, inference, context retrieval, agent orchestration, and continuous optimization.
- Successful AI depends on high-quality, AI-ready data and a context layer that transforms structured and unstructured information into reliable knowledge for models.
- Infrastructure, data, context, models, orchestration, applications, and governance work together to determine AI performance, scalability, security, and cost.
- Security, compliance, observability, and policy enforcement must span the entire AI stack to ensure safe and trustworthy AI systems.
- Organizations need to go beyond the model to an integrated AI infrastructure that can scale, adapt, and reliably support real-world applications over time.
What Is the Modern AI infrastructure stack?
The modern AI infrastructure stack is a layered architecture that enables organizations to build, deploy, and operate AI applications at scale. These could include customer support assistants, enterprise search, document intelligence, and more. Unlike traditional IT infrastructure that was built for databases, business applications, and deterministic software, the AI stack is designed to support compute-intensive model training and inference, context retrieval, agent orchestration, and continuous monitoring of probabilistic systems.
- At its foundation, the stack provides the specialized compute, data storage, and networking required to run large AI models efficiently.
- Above this sits the context layer, which prepares and retrieves structured and unstructured information, providing models with the context they need to generate accurate and trustworthy responses.
- Model execution and serving layers optimize inference performance, while orchestration frameworks coordinate multi-step workflows, tool use, and autonomous agents.
- The upper layers focus on governance, observability, and operational management. These capabilities monitor model behavior, track quality and costs, enforce security policies, and ensure AI systems remain reliable and compliant in production.
Why the infrastructure stack matters for AI outcomes
The success of an AI application depends on far more than the underlying model. While foundation models provide the core reasoning capabilities, the surrounding infrastructure determines how reliably, efficiently, and securely those capabilities are delivered in production. This is especially true in the current foundational models landscape, where giants like Anthropic, OpenAI and Google Gemini provide the models the majority of the industry relies on.
AI infrastructure components handle critical tasks like retrieving context, managing memory, coordinating multi-step workflows, executing inference, and monitoring performance. When this stack is poorly designed, even the most advanced models suffer from high latency, inaccurate outputs, or system failures.
A key design principle is separating enterprise knowledge and application logic from the underlying model. Rather than embedding long-term memory or business context inside a specific model, organizations increasingly maintain these assets in independent data and context layers. This allows applications to switch between models as new capabilities emerge, costs change, or providers become unavailable, without disrupting users or losing organizational knowledge. Plus, because knowledge lives in a separate layer, updates to enterprise information take effect immediately without retraining or redeploying the model.
Looking forward, as AI evolves from simple chat interfaces to autonomous agents capable of planning and executing complex workflows, infrastructure becomes even more important. It orchestrates interactions between models and tools, manages state across long-running tasks, enforces governance and security policies, and provides the observability needed to evaluate and continuously improve AI performance.
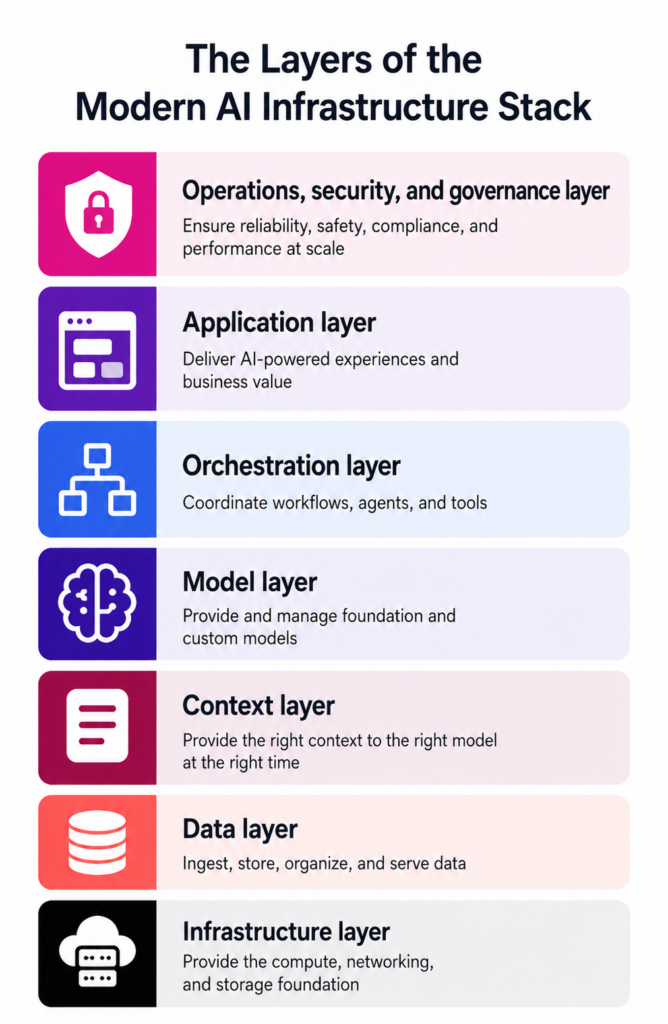
The layers of the modern AI infrastructure stack
Modern AI infrastructure is built as a series of interconnected layers, each responsible for a different part of the AI lifecycle. While vendors may organize these layers differently, most production architectures follow the same progression: infrastructure provides the computing foundation, data supplies the information models learn from, the context layer delivers relevant knowledge during inference, orchestration coordinates workflows, and governance ensures systems remain secure, compliant, and reliable.
Separating the AI agent infrastructure stack into layers allows organizations to evolve individual components without redesigning the entire platform. All while supporting increasingly complex AI workloads.
1. Infrastructure layer
What it is: The infrastructure layer provides the compute, networking, and storage resources that power AI workloads. This includes GPU and TPU clusters, high-performance CPUs, distributed storage, cloud infrastructure, Kubernetes environments, networking fabrics, and edge infrastructure for low-latency inference.
Considerations: Unlike traditional application infrastructure, AI infrastructure must support massive parallel computation, high-throughput data movement, and elastic scaling for both model training and real-time inference.
Value: Performance at this layer directly affects training speed, inference latency, availability, and operating costs.
2. Data layer
What it is: The data layer collects, stores, transforms, and manages the structured and unstructured information that AI systems depend on. It includes data lakes, lakehouses, warehouses, streaming platforms, feature stores, ETL and ELT pipelines, metadata catalogs, and data quality tooling.
Considerations: AI applications place greater demands on this layer than traditional analytics because they consume diverse data types, including documents, images, audio, video, logs, and transactional records. They also require continuous ingestion rather than periodic batch processing.
Value: Reliable, well-governed data is the foundation of accurate models and trustworthy AI outputs.
Context layer
What it is: The context layer has become one of the defining characteristics of modern AI infrastructure. Foundation models possess broad knowledge, but they do not inherently know an organization’s latest documents, customer records, policies, or operational data. Plus, if the data is unstructured, they might not possess the capability to accurately reason over it. The context layer bridges that gap by preparing and contextualizing the data, allowing models and AI agents to generate trustworthy responses grounded in current enterprise knowledge rather than relying solely on their training data.
Considerations: Effective context engineering requires cleaning and normalizing data, modeling relationships, incorporating domain knowledge, retrieving the right context for each task, maintaining explainability and lineage, enforcing governance and security, and continuously updating context as the business evolves.
Value: By supplying the right context for every request, the context layer reduces hallucinations, improves factual accuracy, and enables AI applications to reason over proprietary and continuously changing information without retraining the underlying model.
Flexor is the unstructured context data layer, transforming data like PDFs, calls, emails and chats into clean, unified, contextualized, AI-ready data with ACE (AI Context Engine).
Model layer
What it is: The model layer contains the ML and foundation models that perform reasoning, prediction, classification, generation, and other AI tasks. It includes open-source and proprietary LLMs, multimodal models, traditional ML models, fine-tuned models, inference engines, and model registries.
Considerations: Organizations increasingly treat models as interchangeable components, selecting different models based on cost, latency, reasoning capability, or domain-specific performance rather than building applications around a single provider.
Value: Delivers the intelligence that powers AI applications, enabling organizations to automate tasks, generate content, analyze data, and make decisions while optimizing for accuracy, speed, and cost.
Orchestration layer
What is it: The orchestration layer coordinates how AI systems operate across multiple services and workflows. It manages prompt execution, retrieval pipelines, tool calling, agent workflows, API integrations, workflow automation, and interactions between models and external systems.
Considerations: Orchestration frameworks should support multi-agent workflows, long-running state management, flexible tool integrations, observability, policy enforcement, fault tolerance, and interoperability across models and infrastructure. The framework should be able to evolve as AI applications become more autonomous and complex.
Value: Turns individual AI capabilities into cohesive, production-ready applications by enabling reliable end-to-end execution, reducing operational complexity, and allowing autonomous agents to perform complex business workflows with minimal human intervention.
Application layer
What it is: The application layer is where users interact with AI capabilities. It includes chatbots, copilots, enterprise search, recommendation systems, customer support assistants, coding assistants, business automation tools, and domain-specific AI applications.
Considerations: Although this is the most visible layer, it depends entirely on the services beneath it. The quality of the user experience reflects the effectiveness of the infrastructure, data, context, models, and orchestration working together behind the scenes.
Value: Delivers measurable business outcomes by embedding AI into everyday workflows, improving productivity, accelerating decision-making, enhancing customer experiences, and enabling users to interact with complex AI capabilities through intuitive, task-specific applications.
Operations, security, and governance layer
What it is: The operational layer includes observability, model evaluation, logging, cost monitoring, security controls, identity and access management, compliance, data governance, lineage tracking, and responsible AI guardrails.
Considerations: Running AI in production requires continuous monitoring and governance across every layer of the stack.
Value: These capabilities help organizations detect performance regressions, identify hallucinations, manage infrastructure costs, protect sensitive data, and satisfy regulatory requirements.
Where Most Teams Get the Infrastructure Stack Wrong
Building a modern AI infrastructure stack is a massive paradigm shift. Because the field is moving so quickly, engineering and leadership teams might fall into traps that lead to soaring cloud bills, brittle applications, and failed production deployments.
The most common architectural mistakes occur across three major areas:
1. Hardcoding the Application to a Single Model
Many teams kick off their AI journey by building their entire orchestration and data pipeline around a specific foundation model’s API. This creates tight coupling, making the application incredibly brittle. When a provider updates a model, changes its pricing structure, or experiences an outage, the entire application breaks.
The Fix: Build a clean abstraction layer. Treat the model layer as a plug-and-play utility. By decoupling your core application logic and enterprise knowledge from the specific model, you can swap providers or route tasks to different models based on real-time cost, latency, and reasoning requirements.
2. Over-Investing in Model Fine-Tuning Instead of Context
There is a common misconception that the best way to teach an AI about your business is to fine-tune a model on your proprietary data. Fine-tuning is expensive, time-consuming, and embeds a static snapshot of data that quickly becomes outdated. It changes how a model behaves or formats text, but it is highly inefficient for teaching a model facts.
The Fix: Prioritize a robust context layer. Provide agents with clean and contextualized data when they need it. Save fine-tuning for specific use cases like learning specialized medical terminology or enforcing a unique brand voice.
3. Neglecting “Day 2” Operations and Guardrails
It is surprisingly easy to build a proof-of-concept (POC) demo that looks like magic. It is incredibly difficult to run that same system at scale for thousands of concurrent users. Many teams roll out AI applications without building out the operations, security, and governance layer first. They quickly get blindsided by unexpected token costs, unacceptably high latency, data leakage risks, and silent model drift (where outputs degrade over time without throwing explicit errors).
The Fix: Treat LLM observability, cost tracking, and safety guardrails as day-one prerequisites, not afterthoughts. Implement structured logging, real-time evaluation frameworks, and prompt-injection firewalls before your application ever hits a production user.
See how a context layer fits in your AI stack.
FAQs
What makes data AI-ready?
AI-ready data is accurate, structured, governed, and easily accessible by AI systems. It goes beyond simply storing information. It is cleaned, standardized, deduplicated, parsed, enriched with metadata, connected across sources, and provided with the context models need to understand its meaning. For organizations, this increasingly includes making unstructured data such as Word documents, PPTs, emails, conversations, and PDFs ready for agentic applications.
How is the modern AI stack different from a traditional data stack?
Traditional data stacks were built to support reporting, dashboards, and business intelligence, where humans consume structured information. The modern AI stack is designed for AI systems that continuously retrieve, reason over, and generate outputs from both structured and unstructured data. It adds capabilities such as vector search, context engineering, model orchestration, inference infrastructure, and AI governance to support real-time, intelligent applications.
What role does unstructured data play in the AI infrastructure stack?
Unstructured data contains most of an organization’s business knowledge, including emails, contracts, customer conversations, support tickets, documents, and knowledge bases. Since AI applications rely on business context to generate accurate responses, organizations must transform this information into structured, unified, searchable, and governed context that AI systems can retrieve and reason over. Without it, even the most advanced models produce incomplete or inaccurate results.
How do teams know when their AI infrastructure is ready for production?
Production-ready AI infrastructure delivers reliable, secure, and scalable AI applications. Teams should be able to demonstrate high-quality data pipelines, trusted context retrieval, predictable model performance, orchestration for complex workflows, governance and security controls, monitoring for cost and quality, and the ability to scale across users and use cases. If these capabilities are missing, AI pilots often struggle to transition into production.
