
Unstructured data preparation
Transform your unstructured, fragmented data into clean, structured, and context-rich inputs that AI can reliably understand and act on
Emails
Calls
Documents
Messages
Testimonials
Notes
Surveys
Agent logs
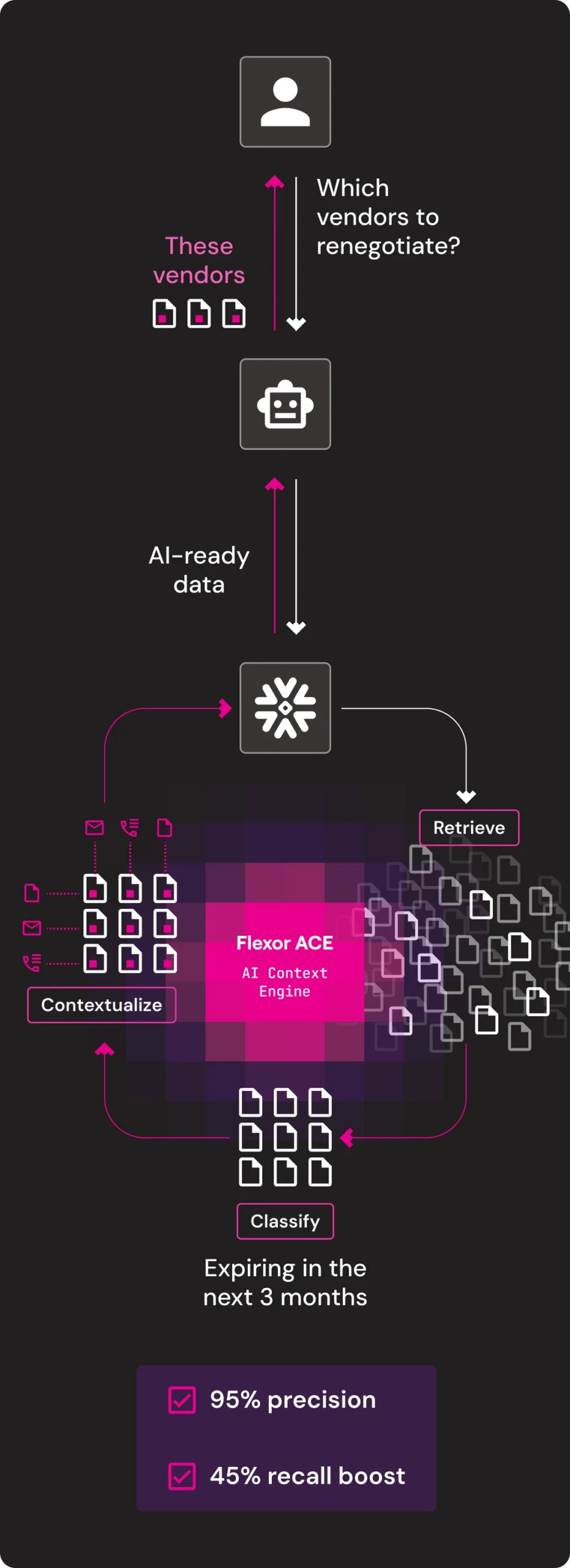
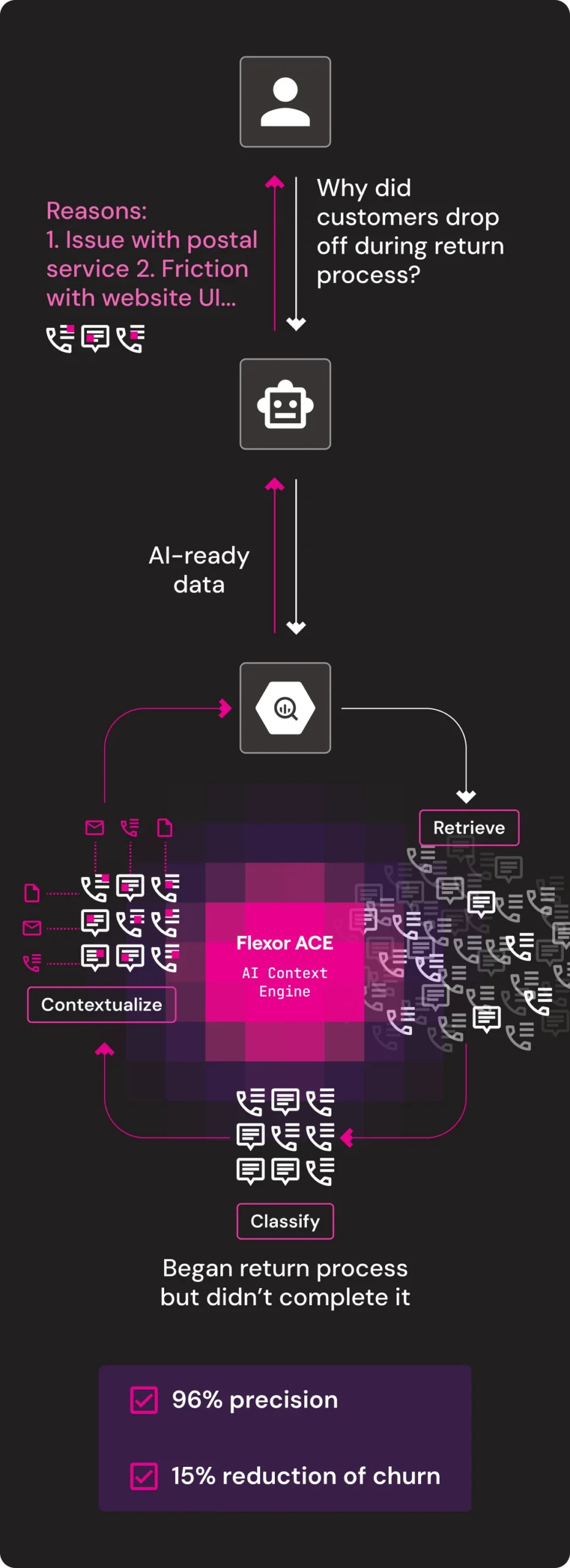
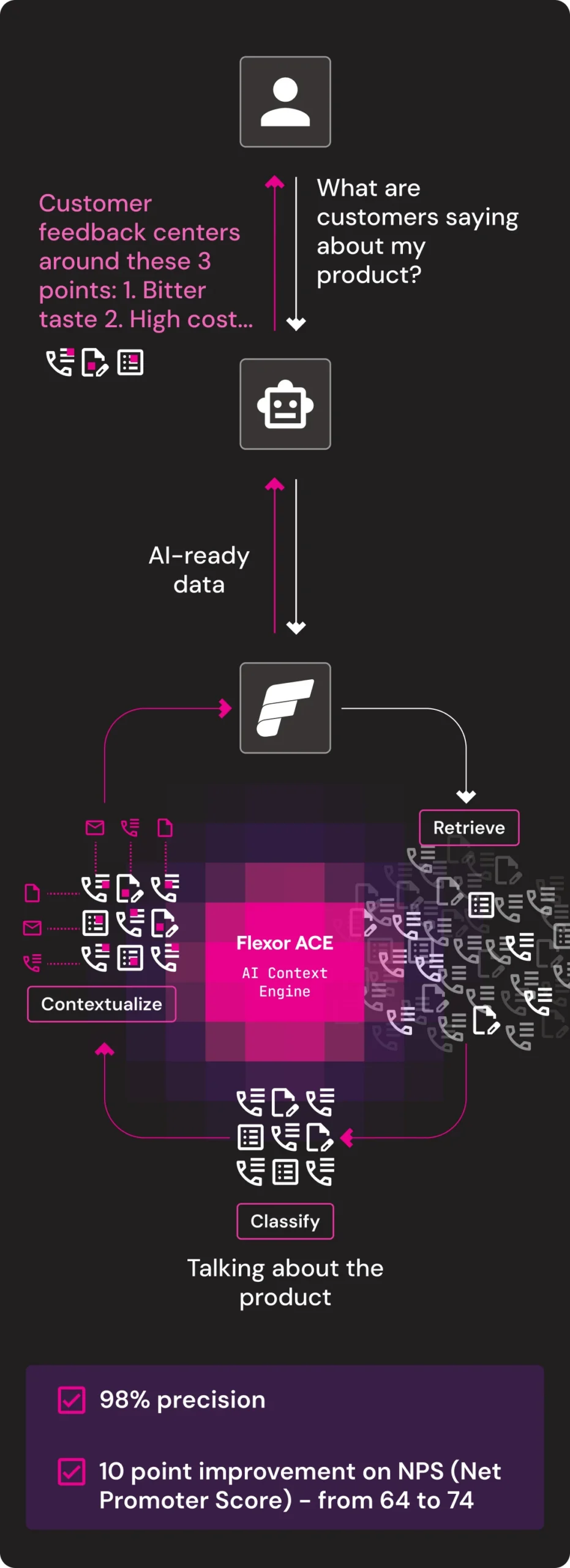
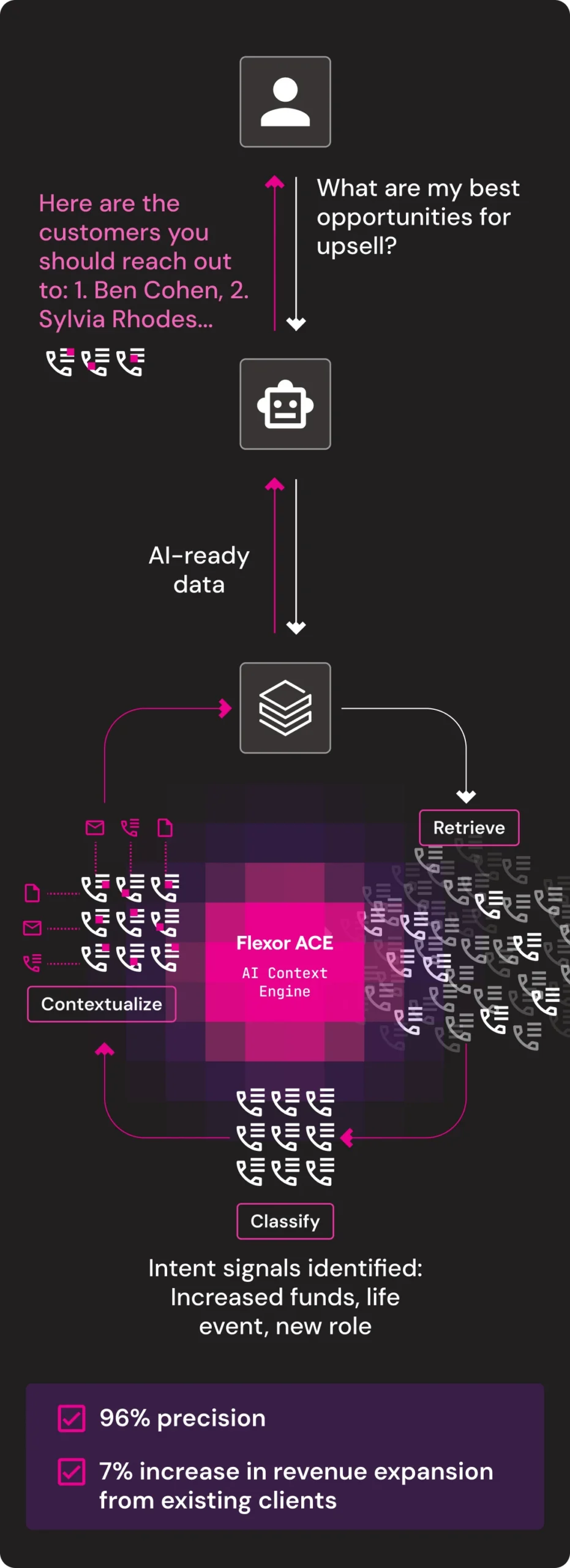
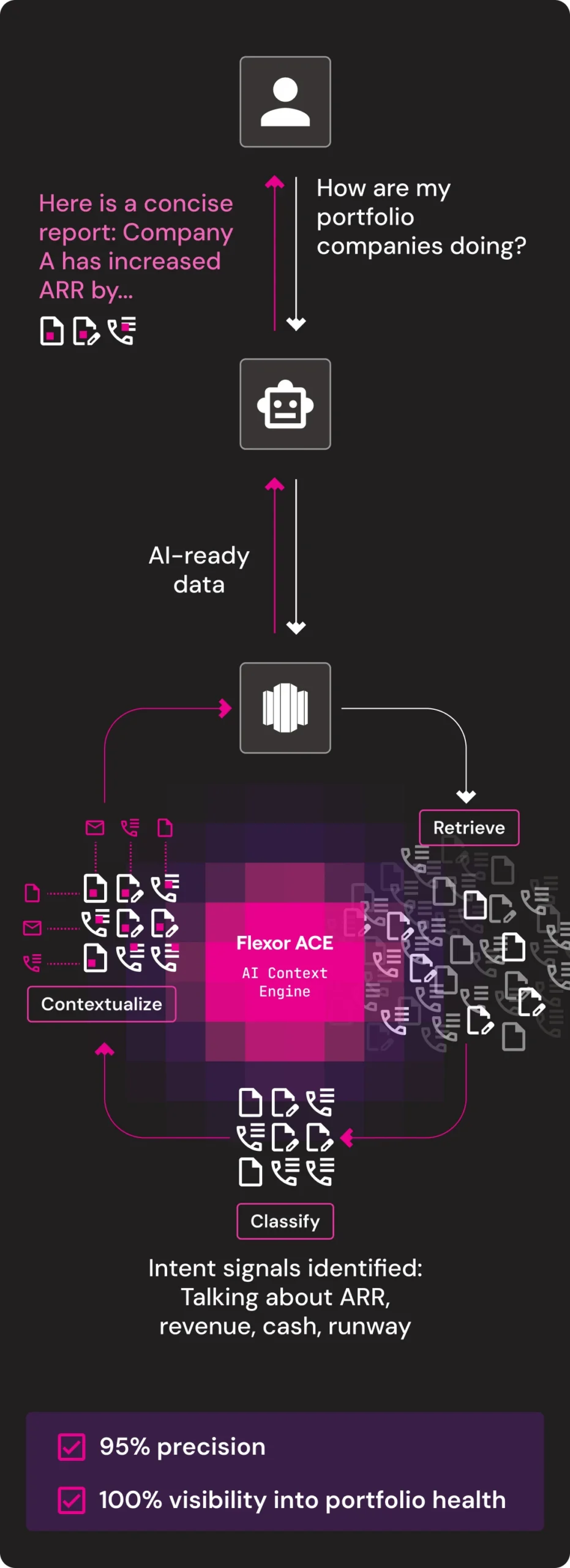
Flexor transforms enterprise unstructured data like emails, PDFs, calls and chats into clean, unified, contextualized, AI-ready data with ACE (AI Context Engine), ensuring that every AI system operates on the data that’s relevant to your business.
THE PROBLEM
Why AI trust breaks at the unstructured data layer
AI is only as trustworthy as the data behind it. AI systems fail when the data they operate on is incomplete, noisy, and irrelevant. The result: unreliable outputs, inconsistencies, hallucinations, and unnecessary costs.
- Fragmented across systems and silos
- Duplicate and redundant
- Low-quality, noisy and irrelevant
- Inconsistent across formats and schemas
- Lacks unified context across domains
- Fragmented across languages
The Solution
Flexor makes unstructured data AI-ready
Large-scale data cleanup
Clean data, clear signal
Flexor removes repetitive content, stale information, signatures, headers, footers, disclaimers, formatting residue, and unnecessary boilerplate across sources.
For example, a support ticket history may contain ten replies but only two lines of new information in each message, surrounded by copied thread chains, signatures, and legal footers. Flexor compresses the record into the meaningful conversation, preserving context while eliminating waste.

Higher model accuracy by increasing signal density in every prompt and retrieval result
Faster responses through smaller context payloads and less unnecessary processing
Lower token, storage, and compute costs across indexing and inference workloads

Deduplication at scale
One truth, not ten copies of it
Flexor detects and eliminates repeated documents, overlapping records, cloned conversations, and near-duplicate content across repositories.
For example, a policy document emailed to twelve teams, uploaded to three intranets, and pasted into a wiki becomes one canonical record.
Higher retrieval precision and faster query results
Reduced storage, indexing, and embedding costs
Schema unification
Every system, one shared structure
Flexor converts data from disparate systems into a consistent, normalized structure so AI tools can process everything in the same way, not incompatible objects from different worlds.
For example, a CRM record, a helpdesk ticket, and a spreadsheet export all describe the same customer interaction. Flexor maps each into aligned entities, fields, and relationships, making them seamless to combine without complex joins or post-processing.
Faster analytics, search, and AI workflows through pre-aligned, ready-to-use data
Lower compute and token costs by eliminating repetitive transformations and duplicate processing
Faster time to value with less engineering effort spent reconciling incompatible systems


Noise filtering
Keep garbage out of the pipeline
Flexor identifies and removes corrupted characters, malformed exports, encoding issues, OCR errors, placeholder text, empty records, duplicate fragments, and system artifacts with no analytical value before any of it enters the knowledge base and degrades downstream reasoning.
For example, a legacy export may contain thousands of rows filled with unreadable symbols, escaped HTML strings, null placeholders, and incomplete records. Flexor filters the noise automatically, ensuring only usable content reaches downstream systems.
Improved retrieval precision by preventing junk data from contaminating search results
Lower embedding, indexing, and storage costs by excluding worthless records upfront
More reliable AI outputs through cleaner grounding data and fewer irrelevant inputs
Multilingual enterprise data
Full global knowledge, no language gaps
Flexor ingests and normalizes enterprise data across languages and regions, aligning equivalent concepts into shared representations regardless of how or where they were written.
For example, a contract clause in German, a compliance note in Japanese, and an HR policy in Spanish all resolve to the same unified meaning, so agents reason over the full scope of organizational knowledge, not just the English-language slice.
AI agents draw on the complete enterprise knowledge base, eliminating blind spots caused by multilingual fragmentation
Language-agnostic ingestion means no separate pipelines, no missed context, and no bias toward any single region or language
Operational costs of supporting a multilingual enterprise – slashed

Delivering context for AI
Meet ACE – The AI Context Engine. ACE automates pre-processing and context building with tailored LLMs and VLMs in a robust multi-phase process, giving you everything you need to turn your enterprise unstructured data into context for AI, straight out of the box.
Tackle the toughest challenges holding back your enterprise, today
Here are some of the ways enterprises use Flexor’s AI Context Engine, ACE, across departments.

Procurement Optimization

Churn Mitigation

Product Discovery

Upsell Identification

Portfolio Management
Procurement Optimization
Churn Mitigation
Product Discovery
Upsell Identification
Portfolio Management
Ready to give your AI agents the context they actually need?
Transform your unstructured data into a competitive advantage.
Frequently asked questions
Why can’t AI agents work directly on raw enterprise data?

Raw enterprise data is typically fragmented, duplicated, inconsistent, and full of noise. Without preparation and context, AI agents produce inaccurate results, hallucinate, and struggle to deliver consistent outcomes.
What types of unstructured data can Flexor prepare?
Flexor works across all types of unstructured enterprise data, including emails, contracts, PDFs, calls, CRM notes, call recordings, and more.
How does Flexor reduce hallucinations?
By filtering out irrelevant data, removing duplicates, and enriching inputs with business context, Flexor ensures AI agents operate only on high-quality, relevant information, significantly reducing hallucinations and inaccuracies.
How does Flexor lower AI costs?
Flexor reduces the volume of data processed by eliminating redundancy and surfacing only what’s relevant. This can cut token usage , significantly lowering inference and processing costs.
Can Flexor handle multilingual data?
Yes. Flexor normalizes and aligns data across languages, enabling AI agents to operate on a unified understanding of your global data without separate pipelines or translation gaps.
