
Structuring the unstructured
Transform your unstructured data into structured schemas your AI agents can act on.
Emails
Calls
Documents
Messages
Testimonials
Notes
Surveys
Agent logs
Flexor transforms enterprise unstructured data like emails, PDFs, calls and chats into clean, unified, contextualized, AI-ready data with ACE (AI Context Engine), ensuring that every AI system operates on the data that’s relevant to your business.
THE PROBLEM
90% of organizational data is trapped in unstructured sources
Most valuable business signals do not live in clean databases. They live inside conversations, PDFs, contracts, support tickets, emails, meeting notes, and free text. That means critical information is difficult to search, measure, automate, or activate.
- Customers asking for discounts in emails or calls
- Complaints hidden inside support conversations
- Competitors mentioned during sales calls
- Requested product features buried in notes
- Contract clauses inside legal documents
- Invoice totals trapped in PDFs
- Reasons for churn hidden in conversations
The Solution
Flexor transforms unstructured data into AI-ready business context
Automated data preparation
Clean, deduplicated, normalized inputs
Flexor cleans, deduplicates, translates and parses your unstructured data, to automatically remove the noise that degrades AI output.
For example, email threads repeat the same content dozens of times across threads. Flexor identifies the canonical message, eliminates redundant copies, and delivers a single, clean record to AI agents.

AI agents work with clean, right-sized and reliable inputs to generate accurate, consistent results.
Token costs are reduced by as much as 90%


Unified schema
Standardized once, usable everywhere
Flexor maps all unstructured data to a shared schema, so data from every source follows the same consistent structure and level of granularity.
For example, a contract clause, a support conversation, and an expense submission can all be mapped into aligned entities, attributes, and relationships.
AI agents reason across domains through a single, consistent structure, ensuring accuracy across fragmented and conflicting data
No redundant processing and context building or duplicate pipelines across data sources
Multilingual enterprise data
Full global knowledge, no language gaps
Flexor ingests and normalizes enterprise data across languages and regions, aligning equivalent concepts into shared representations regardless of how or where they were written.
For example, a contract clause in German, a compliance note in Japanese, and an HR policy in Spanish all resolve to the same unified meaning, so agents reason over the full scope of organizational knowledge, not just the English-language slice.
AI agents draw on the complete enterprise knowledge base, eliminating blind spots caused by multilingual fragmentation
Language-agnostic ingestion means no separate pipelines, no missed context, and no bias toward any single region or language
Operational costs of supporting a multilingual enterprise – slashed


Intelligent parsing across any format
Every document, regardless of shape
Flexor extracts data from documents regardless of template, layout, or visual structure, adapting automatically to variation across vendors, regions, and internal teams.
For example, invoices from a hundred different suppliers might each use a different layout, currency format, and line-item structure. Flexor parses all of them consistently, pulling the same fields with the same accuracy, without a custom template for each vendor.
AI agents receive structured, reliable data from every document type
Eliminates costly per-template maintenance, manual rework, and exception handling at scale
Data enrichment and context expansion
Raw records turned into business-ready intelligence
Flexor enriches unstructured data with missing context, relationships, classifications, and external or internal reference data, transforming incomplete records into high-value inputs AI systems can reason over.
For example, a customer support ticket containing only an email address and complaint text can be enriched with account tier, open opportunities, product usage history, renewal date, sentiment score, and linked past cases.
AI agents make smarter decisions with richer context, stronger prioritization, and more accurate recommendations
Reduces manual lookups, fragmented joins, and repetitive data stitching across systems, lowering operational and compute costs

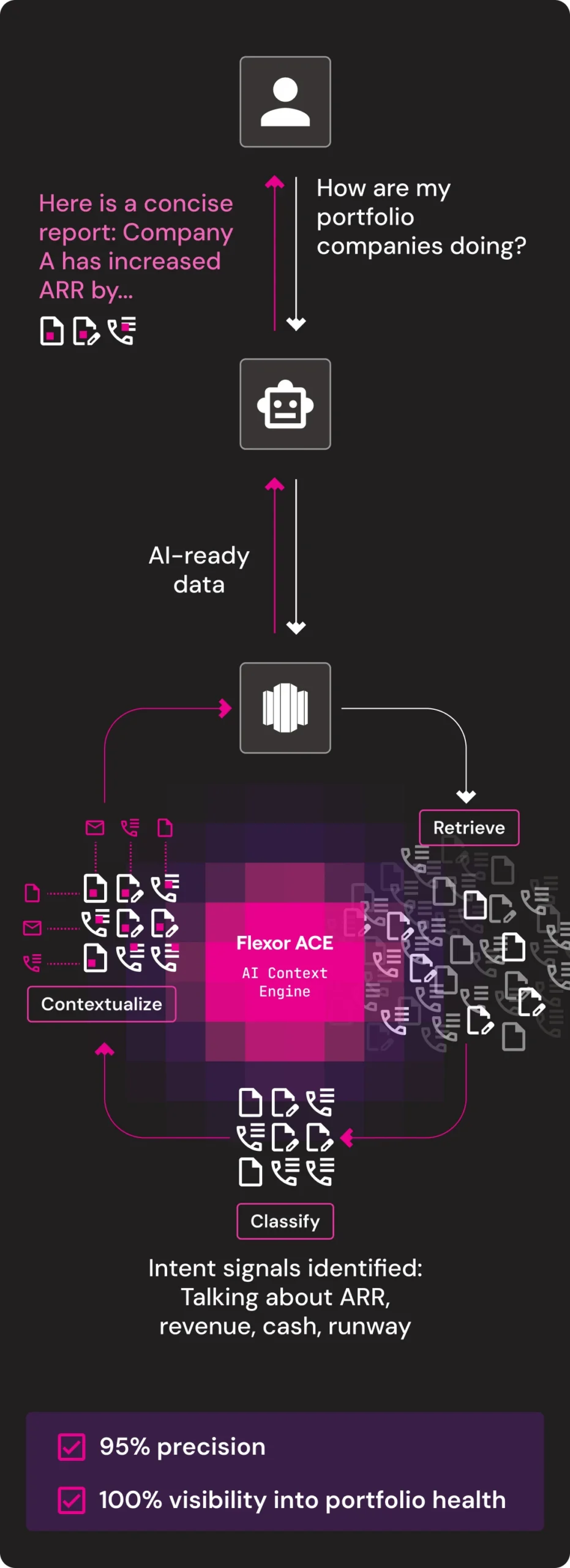
Delivering context for AI
Meet ACE – The AI Context Engine. ACE automates pre-processing and context building with tailored LLMs and VLMs in a robust multi-phase process, giving you everything you need to turn your enterprise unstructured data into context for AI, straight out of the box.
Tackle the toughest challenges holding back your enterprise, today
Here are some of the ways enterprises use Flexor’s AI Context Engine, ACE, across departments.

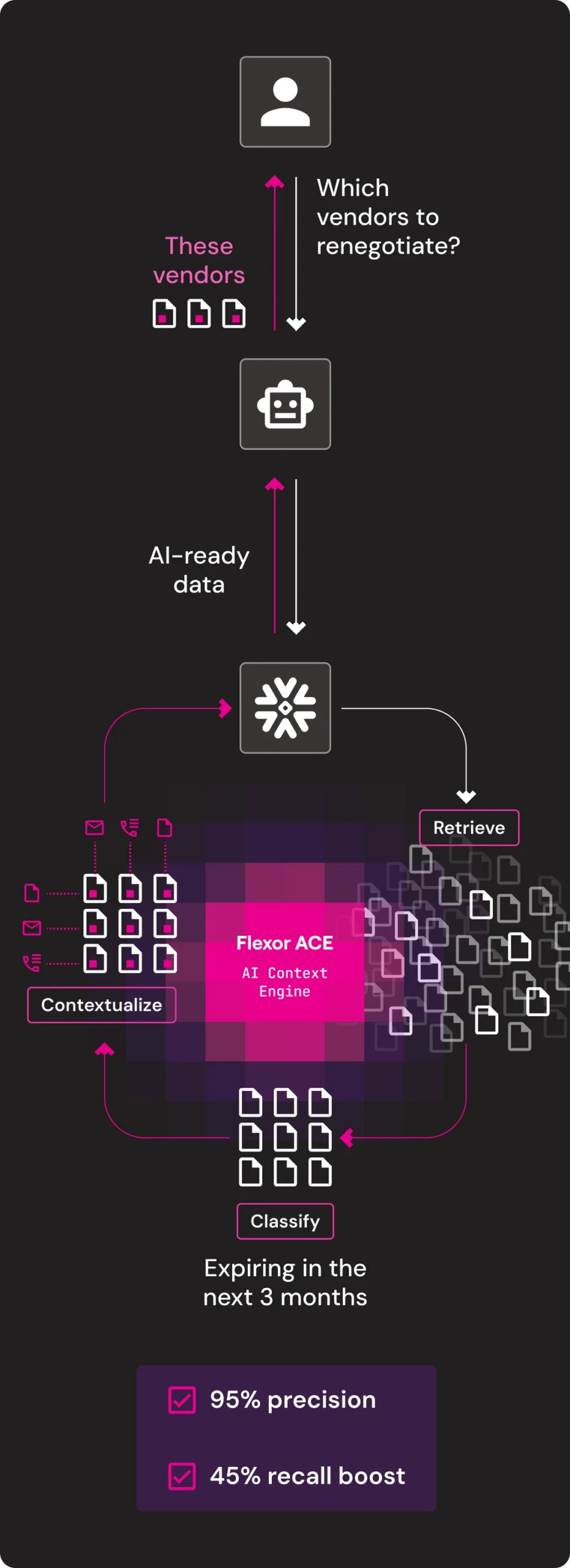
Procurement Optimization

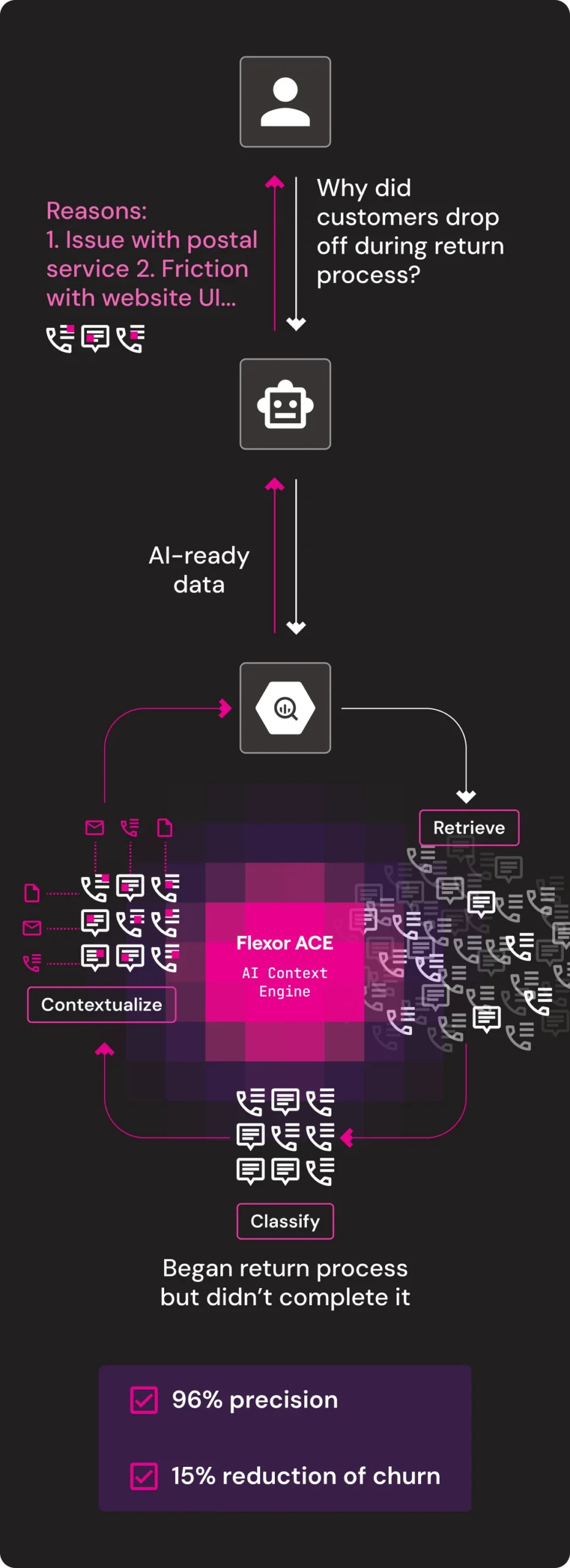
Churn Mitigation

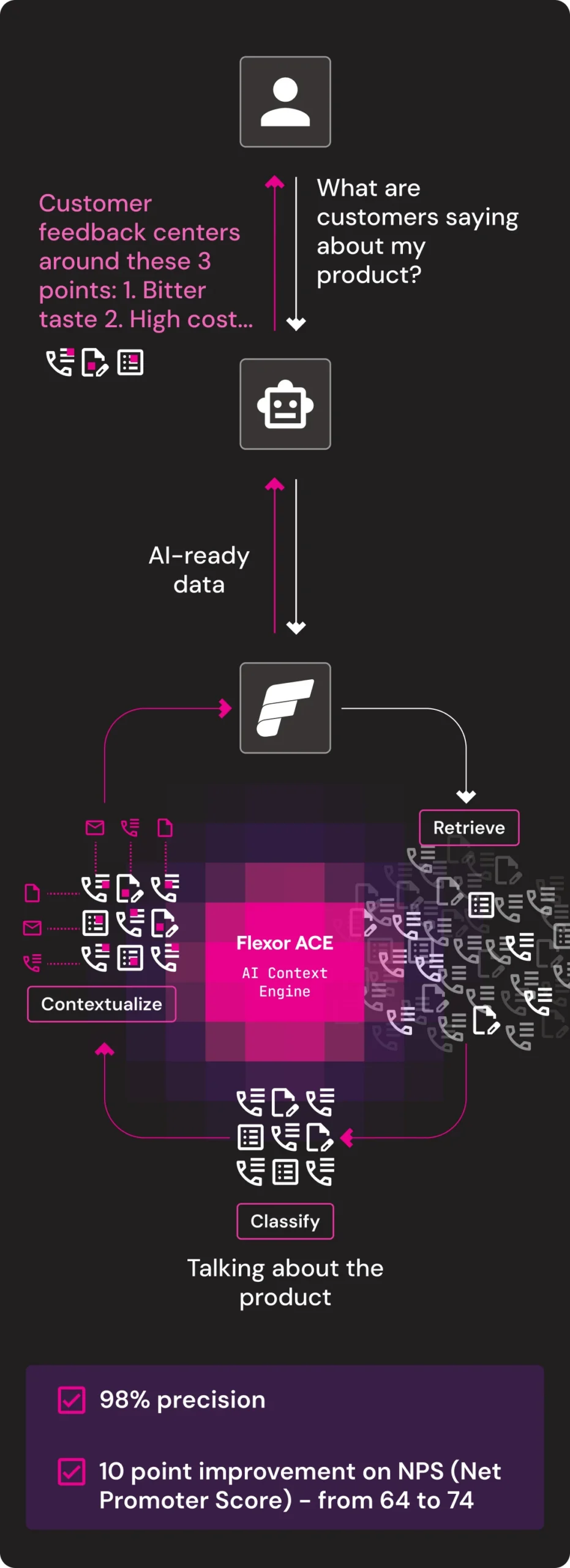
Product Discovery

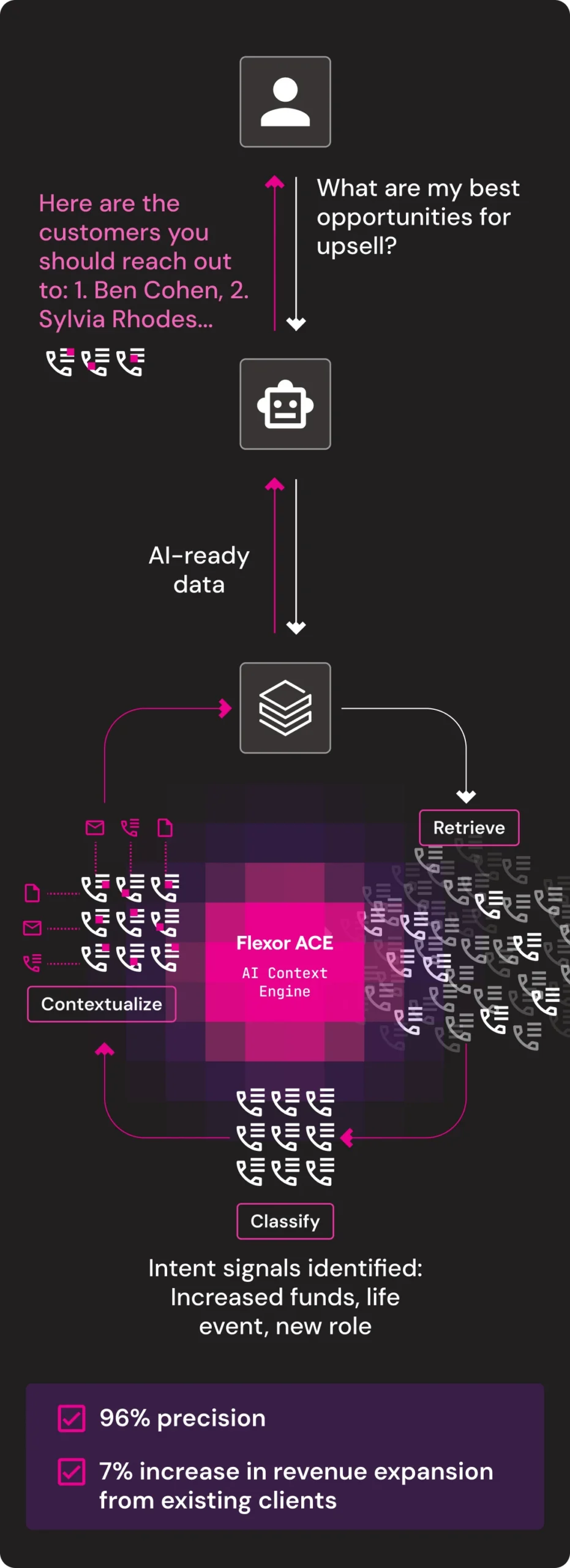
Upsell Identification

Portfolio Management
Procurement Optimization
Churn Mitigation
Product Discovery
Upsell Identification
Portfolio Management
Ready to give your AI agents the context they actually need?
Transform your unstructured data into a competitive advantage.
Frequently asked questions
What does “structuring the unstructured” mean?

It means converting messy business content, like emails, PDFs, calls, chats, notes, tickets, and documents, into clean, structured data that AI systems can search, analyze, automate, and act on.
Why is unstructured data important for AI?
Because much of the most valuable business information does not live in databases. It lives in conversations, documents, contracts, and free text where traditional systems cannot easily access or use it.
What types of data can Flexor process?
Flexor can process enterprise unstructured data such as emails, PDFs, contracts, invoices, call transcripts, meeting notes, chats, support tickets, policies, wikis, and other text-heavy sources.
What is a unified schema?
A unified schema is a consistent structure applied across different data sources. It allows contracts, support conversations, invoices, and other records to be understood through the same entities, attributes, and relationships.
What is data enrichment?
Data enrichment means adding missing business context to raw records. For example, a support ticket can be enriched with customer tier, renewal date, product usage, sentiment, and past interactions.
Do I need separate pipelines for every source or language?
No. Flexor is designed to unify diverse data sources, formats, and languages into one reusable AI-ready context layer.
